Free E-Gov Conference (via webcast) on February 17, 2009
February 11th, 2009
As a follow up to my previous post on e-government, just wanted to let those who are interested know that there's a free conference offered next week that will get much more in-depth about the initiatives for changing the way government uses and disburses information. The conference will also have a particular emphasis on using semantic technologies.
Here are the details:
From E-Gov to Connected Governance: the Role of Cloud Computing, Web 2.0 and Web 3.0 Semantic Technologies
Tuesday, February 17, 2009.
Morning session: 8:30 am EST to 12:00 noon. Afternoon session: 1:00 pm EST to 4:00 pm EST.
Synopsis: “We have a new administration that values transparency, citizen participation, collaboration, information sharing, and internet technology… The purpose of this conference is to operationalize this vision, demonstrate the kinds of changes that are coming to next stage web-based systems in government, and to map the role of information and communication technologies (specifically, cloud computing, Web 2.0, and Web 3.0 semantic technologies) in the evolution of government information systems from e-gov (silos with web front ends) to connected governance (e.g. distributed social computing environments for collaborative work, information sharing, knowledge management, and participatory decision-making.)”
Webcast sign-up here (or, if you are in Washington DC area, you could attend in person)
Further information about the conference can be found here.
 It was intriguing to see how all this newfangled web 2.0 technology was applied during the US presidential campaign this past year (organization, multimedia, etc.). It's also quite interesting to hear about
It was intriguing to see how all this newfangled web 2.0 technology was applied during the US presidential campaign this past year (organization, multimedia, etc.). It's also quite interesting to hear about  Ah, tax season… could there be a more thrilling time of the year?
Ah, tax season… could there be a more thrilling time of the year? Today I came across a
Today I came across a 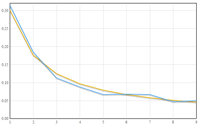 Benford's law is one of those things your high school math teacher would break out on a slow, rainy day when the students' attention span was even lower than usual.
Benford's law is one of those things your high school math teacher would break out on a slow, rainy day when the students' attention span was even lower than usual.