We're pleased to announce that we just released a new upgrade to Kirix Strata, version 4.3! Kudos to our developers for adding a lot of nice features and bug fixes. The full list of notes to this release is below the jump, but here are a few of the bigger changes:
We're pleased to announce that we just released a new upgrade to Kirix Strata, version 4.3! Kudos to our developers for adding a lot of nice features and bug fixes. The full list of notes to this release is below the jump, but here are a few of the bigger changes:
External Database Connectivity
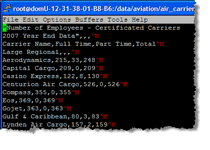
We've really improved the way that Strata works with external databases by optimizing our pass-through queries for databases like Oracle, SQL Server and MySQL. In addition, queries in the query builder that reference external database tables pass the query through to the external database, significantly increasing the speed of queries on external databases. Furthermore, you can now edit individual cells in Strata and have them update in your external database table. This is very welcome news to folks that want to use Strata as a front-end to their external database tables.
UPDATE (04/30/2009): Just a quick note of clarification, on the “read” side, you can work with external databases for things like sorting, filtering, marks, calculated fields, grouping and copying. On the “write” side, we currently only have cell editing available, but will work on adding other features in the future such as append (i.e., insert record), delete, update, and some modify structure operations. If you need these additional “write” features, please send us a note to let us know how you would plan on using them to help us prioritize our development efforts. Thanks dedicated servers!
Improved SQL Support
We added a console panel to allow direct querying of internal and external databases with SQL commands, as well as to provide feedback for database operations and scripts. You can learn more here.
EBCDIC Conversion
Strata now handles EBCDIC. We haven't added copybook support just yet, but you can either manually set your breaks using the text-import or create scripts to convert the EBCDIC file to ASCII format. You can learn more here.
Fixed Length and Delimited Table Export
We've also added Fixed-length export (this also works when using File > Save As External). In addition, we've expanded the text-delimited export so that you can specify your own delimiters, such as pipe-delimited and semi-colon delimited. You can learn more about the new text-delimited functionality here.
Handling Tablenames & Fieldnames with Spaces
One of our most common support questions relates to spaces in a fieldname (like “my field” instead of “my_field”). We've now solved this issue by allowing spaces to be used by enclosing the name in brackets. So, for example, these are now all valid expressions:
[Field 1] * [Field 2]
Field1 * [Field 2]
[Table 1].[Field 1]*[Table 2].Field2
You can learn more here.
Much Much More…
There are plenty of other upgrades like project handling, new keyboard shortcuts, auto-fill group and sort dialogs, new script classes, etc. You can check out all the changes below the jump.
Please download the latest Strata (or just click “Check for Updates” in the Help menu), give it a whirl and let us know what you think!
Read the rest of this entry »


 Yikes. It's been a while. We've been pulled off on myriad other important projects, but happy to announce a new upgrade to Kirix Strata. Better late than never, right… right?
Yikes. It's been a while. We've been pulled off on myriad other important projects, but happy to announce a new upgrade to Kirix Strata. Better late than never, right… right?  We're pleased to announce a minor upgrade to Kirix Strata today,
We're pleased to announce a minor upgrade to Kirix Strata today, 
 In
In  We haven't been doing much regular blogging lately, but we're hoping this will change in the coming weeks.
We haven't been doing much regular blogging lately, but we're hoping this will change in the coming weeks.