Fun (and Fraud Detection) with Benford's Law
Tuesday, July 22nd, 2008
 Benford's law is one of those things your high school math teacher would break out on a slow, rainy day when the students' attention span was even lower than usual.
Benford's law is one of those things your high school math teacher would break out on a slow, rainy day when the students' attention span was even lower than usual.
He'd start out by asking the class to look at the leading digits in a list of numbers and then predict how many times each leading digit would appear first in the list. The students would make some guesses and eventually come to the consensus that the probability would be pretty close — about 11% each.
Then, the teacher would just sit back, smile, and gently shake his head at his simple-minded pupils. He would then go on to explain Benford's law, which would blow everyone's mind — at least through lunchtime.
(Click the image above… or here's an embeddable YouTube version)
Per Wikipedia:
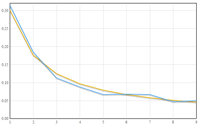
Benford's law, also called the first-digit law, states that in lists of numbers from many real-life sources of data, the leading digit is distributed in a specific, non-uniform way.
Specifically, in this way:
Leading Digit Probability
1 30.1%
2 17.6%
3 12.5%
4 9.7%
5 7.9%
6 6.7%
7 5.8%
8 5.1%
9 4.6%
Again, from Wikipedia:
This counter-intuitive result applies to a wide variety of figures, including electricity bills, street addresses, stock prices, population numbers, death rates, lengths of rivers, physical and mathematical constants, and processes described by power laws (which are very common in nature).
Boiling it down, this means that for almost any naturally-occurring data set, the number 1 will appear first about 30% of the time. And, by naturally occuring, this can mean check amounts or stock prices or website statistics. Non-naturally occurring data would be pre-assigned numbers like postal codes or UPC numbers.
Besides being fun to play with, Benford's is used in the accounting profession to detect fraud. Because data like tax returns and check registers follow Benford's, auditors can use it as a high-level check of a data set. If there are anomalies, it may be worth investigating closer as potential fraud.
If you're interested in further information about fraud detection using Benford's, definitely give these two articles by Malcolm W. Browne and Mark J. Nigrini a read.
Try It Out for Yourself
Take a look at the demonstration video above to see Benford's law in action with data sets from the web. If you'd like to play with it yourself, just install the Benford's Law extension for Kirix Strata™ and have fun.
Also, please note that I used the following data sets in the video, if you'd like to give those a spin:
Wikipedia List of Lakes in Minnesota
US Census Data Sets
Social Blade - Digg Statistics
And here are a few other worthy ones that didn't make it in the video:
NASDAQ Historical Stock Price
Wikipedia List of Countries by Population
And plenty more at Delicious here…
Enjoy!
 If you haven't checked out what the fine folks at
If you haven't checked out what the fine folks at