

Infochimps and Numbrary: More Data Than You Can Shake a Stick At
Thursday, July 10th, 2008
 These are some very good times for those of you out there who like publicdata. I ran across Kevin Chai's research website today that has a nice listing of various data sets, blog articles and other data-related goodies.
These are some very good times for those of you out there who like publicdata. I ran across Kevin Chai's research website today that has a nice listing of various data sets, blog articles and other data-related goodies.
This reminded me of a couple other really interesting websites that are trying to solve the problem of data accessibility. Check ‘em out:
Infochimps.org
Infochimps wins the award for compiling massive data sets. If this is your thing, you may want to have a look. For instance, in a recent blog post, they provided a peek into some of the hidden gems of their collection, including:
- Full game state for every play of every baseball game in 2007, majors and minors. Additionally, for about half of the major league games, pitch by pitch trajectory and game state information. (MLB Gameday)
- Word frequencies in written text for ~800,000 word tokens (British National Corpus)
- All the Wikipedia infoboxes, turned on their side and put into a table for each infobox type.
- 250,000+ Materials Safety Data sheets - the chemical and safety information required by OHSA
- 100 years of Hourly weather data; from 1973 on there's about 10,000 stations all taking hourly readings … put another way, it's 475,000+ station-years of hourly readings and weighs in at ~15 GB compressed.
Break out that baseball data and you'll be sure to impress your friends during the upcoming All-Star game.
As an aside, if any of you do end up taking this data for a spin with Kirix Strata™, let us know how it goes. Strata's got a theoretical limit of about 60 billion records per table. Internally, we've tested on about 1 billion records, but have only pushed it past 100 million records or so in the corporate setting. Strata tends to eat data for lunch, so if you push it past the 100 million record mark, we'd love to hear about it.
Numbrary
I recently ran across Numbrary and, for the little time I've played with it, I'm pretty impressed. It has a lot of public data available with a heavy emphasis on economic indicators but with a load of other stuff too. Best of all, it offers the data to the user in CSV format, which Strata happily opens up directly.
Here's their mission statement, summarized:
Finding data is a pain.
Working with data is a drag.
Talking usefully about data is nearly impossible.
Numbrary® aims to change this.Search engines don't help much. Numbers are not words, which can be scanned and indexed for rapid search and retrieval.
Collections of numbers need as much attention online as do collections of words. With Numbrary®, they will receive that attention.
So, if you need a data set and a Google search set to filetype:csv doesn't help, give these two websites a spin. Got any other good data repositories to share? Let us know.
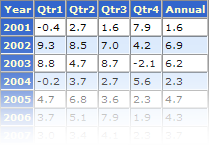
 There's a surprising amount of
There's a surprising amount of