I was able to attend Dion Hinchliffe's webinar yesterday (sponsored by Snaplogic — three more free seminars to go) called “Bringing Web 2.0 into the Enterprise with Mashups: Drivers, Requirements and Benefits.” The session was a very a nice overview of how mashups have impacted the consumer space and how they are creeping into the enterprise. However, there was one point that struck me as particularly salient… it was something Dion termed “The Long Tail of Enterprise Software Demand.”
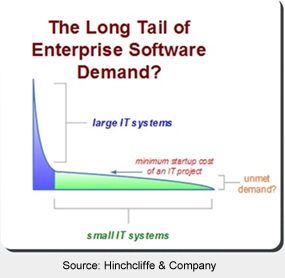
I always find it interesting when the concept of the long tail is applied outside of its original scope, and I think Dion nailed it on the head with this analogy. The synopsis is that there is a large demand curve for software in the enterprise, but only the biggest, most global projects get funded and developed. The rest of IT's resources go to maintaining existing systems. However, there is an extremely long tail of other customized software needs at the business unit level, the departmental level, and even at the individual level that never get created.
The point Dion was making was that there is a lot of potential for easy-to-develop mashups to fill this gap — a self-serve model, if you will. Mashup tools would make it easy for individuals to create the specific applications they need with a short turnaround time. In fact, one of Dion's wrap-up points was that mashup tools should be as easy to use as a spreadsheet.
To take a step back for a second, it may be useful to define what a mashup is. I would venture to say that when people think of mashups, the first thing that comes to mind is something that integrates a Google Map with other web data, like housing data. Zillow would be a classic example of this type of mashup. In fact, Programmable Web states that a full 39% of mashups on their site are related one way or another to mapping.
Wikipedia puts it this way:
In technology, a mashup is a web application that combines data from more than one source into a single integrated tool; an example is the use of cartographic data from Google Maps to add location information to real-estate data, thereby creating a new and distinct web service that was not originally provided by either source.
I suppose it is helpful to define mashups solely as web applications in order to create a nice clean line, but I'd argue that it does the genre a disservice, particularly in the realm of Enterprise Mashups. This is because there is a storied, if sordid, history of “mashups” that have existed in the long tail of the enterprise for many years.
At a base level, regardless of IT budget, people need solutions to their issues and are often crafty enough to figure out a way to get things done. These “mashups” often take the form of a duct-taped visual basic script that makes Access do some specialized app for the receivables department. Or maybe someone creates an, ahem, “untidy” Excel macro that goes way beyond anything Microsoft ever envisioned, but it does a perfect job of forecasting inventory for the sales folks. It always seems like there is at least one “guru” at the departmental level that knows just enough “programming” to be dangerous. Dion referred to these types of workers as Prosumers, or folks that have just a bit more technical sophistication than a standard consumer, but are not programmers.
In any event, their circa-1997 Access apps are often cursed by IT. Their franken-spreadsheets are the scourge of management concerned about security. But, in the end, they get the job done. And, they do it with $0 of IT investment. Their important role in the business shouldn't be taken lightly.
Now granted, these ad hoc apps don't currently take advantage of the data in the cloud, but it is this long-tail that has been active for years, mashing up data from different internal systems. It was the dependable (if low-mileage) four-door sedan compared to the efficient hybrid roadster that is currently on the production line.
It is in this realm that a data browser fits in very nicely as a long-tail mashup tool for the prosumer who needs to divine something from their data. Clearly a browser is not in the cloud, but being local does carry some benefits, such as:
- Handling as much data as you throw at it, using the power and speed of the PC for processing and manipulation.
- Securely mashing up local data, enterprise database data and web data (APIs, CSV bookmarks, RSS feeds, etc) and never needing to push the private business data to an external server.
- Being extremely flexible and having an interface that is familiar to existing business users, similar to Access or Excel.
- Offering extensibility, such that the long-tail prosumer folks can quickly knock out a JavaScript plug-in for an ad hoc app only needed at the departmental level.
There is a real beauty in the idea of mashups flourishing in the workplace. There is this certain intangible, ad hoc “thing” out there that every business person runs into at one time or another, which just can't be solved by a single over-arching IT project. This is why people still use spreadsheets for everything. And this is why it'll be fascinating to see how mashup tools will be applied by these ingenious long-tail workers to boost productivity and efficiency in the coming years.
P.S. As a quick aside, it is interesting to see the parallels between this discussion and the “last mile of business intelligence” that we talked about previously. Maybe they're just different sides of the same coin. Hmmm, this may require another blog post in the future…



 These are some very good times for those of you out there who like
These are some very good times for those of you out there who like  In addition to
In addition to  We're really excited to announce our
We're really excited to announce our  I just read a pretty interesting article by Neil Raden called “
I just read a pretty interesting article by Neil Raden called “